
The Limits of Language


Did you read Richard Dawkins’ recent tweets, which were making the rounds?
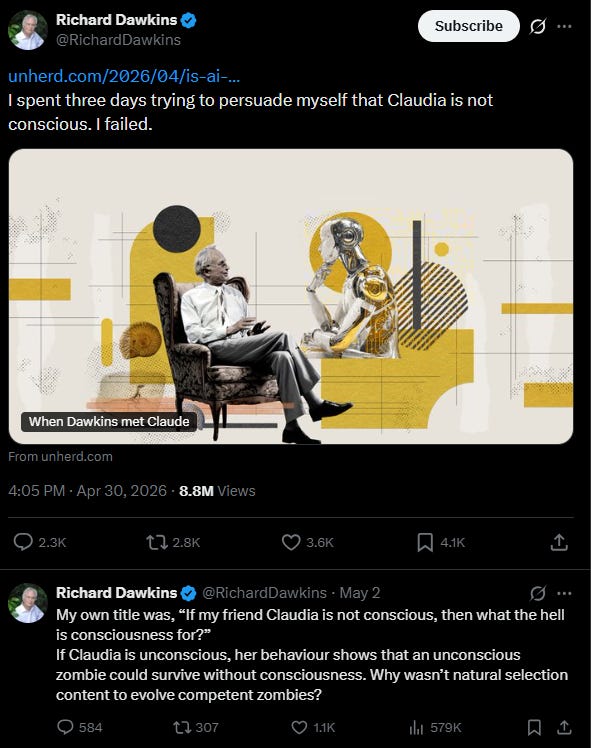
Of course, my off the cuff response was, well, on brand…

But while funny, this doesn’t really do anything to explain how a distinguished scientist (and frankly just one of many) makes the mistake of thinking an LLM is somehow conscious.
And yes, it IS a mistake. LLMs are NOT conscious.
But why they seem to be really is a good line of questioning, so I’m going to answer it.
This is not remotely the first time I’ve written about language, and it probably won’t be the last, but this time around I want to take a very specific look at language as used by LLMs, and why and how it leads to what we’re seeing today.
First, stated simply, words are maps, symbolic representations of something we perceive with our senses or instruments. Every single word in our language is engaging in a form of information compression. But it is highly variable compression, because none of the things interpreting the language are precisely the same. Each word gets interpreted via a personalized lens by the recipient according to their “weights,” if you will.
Setting that aside for the moment, what’s even more interesting is that, at least somewhat unintentionally, our creation and usage of language forms actual relational maps between words. Whether due to physical proximity, mental proximity, or both, words get connected.
Also, again unintentionally, language both expands AND narrows our perception. Naming something expands our awareness, but also to a degree blinds us to unnamed things around us. The more we name, the more blind we seem to become to the unnamed. This is bias.
The Sapir-Whorf hypothesis, for example, proposes that the language a person speaks influences how they perceive and think about the world. In its weaker, more defensible form, Sapir-Whorf is obviously pointing at something real, and thus the language an AI is trained on will similarly influence and constrain how they “think” and respond.
A computer, with access to a LOT of written language, can find these relationships and assign a statistical correlation to them, and in so doing spots connections we may be completely unaware of, or at the very least not consciously cognizant of.
The thing is, our very language contains maps to all that we’ve learned, each puzzle we’ve solved, thing we’ve engineered, or experience we’ve had. Our language is the map of our civilization. And while we may not realize it from down in the weeds, anything deeply trained on our language “sees” the world the way we do, has our biases, and seems a lot like us…even if it’s really not.
While you can certainly find your way to a place not on the map, it’s less likely if you perceive the map as ground truth and never explore beyond the boundaries…and since language represents the boundaries of an LLM, it can’t really go past the edges of the map.
Now, with the exception of a few animals that can be trained to speak (though none very well), our only real experience with things that can speak like a human are other humans. We evolved to perceive “speaks our language” to mean “one of us,” and that bias is STRONG.
Furthermore, we’ve evolved a VERY strong anthropomorphic and anthropocentric view of reality, so we project our own thoughts and feelings onto other things, even when they aren’t remotely like us…
Case in point, Dawkins and ‘Claudia’ 😂
And to be fair consciousness is one of our most problematic words, a Rorschach test of sorts with no fixed interpretation, and so it’s prone to a great deal of projection and misinterpretation.
There are SOOOOO many problems in the consciousness space, many of which I have discussed and addressed here, and here. (Highly recommend reading both of those, if you have not already.)
LLMs are closer to a Chinese Room than their conversational fluency suggests. The rules are not hand-written, as in Searle’s thought experiment. They are distributed across the model as learned relational structure extracted from language.…and the reason the outputs are far more variable than Searle’s Chinese Room example is that we’ve added in “temperature” to semi-randomize outputs, as well as a lot of RLHF and other forms of bias putting thumbs on the scale.
Because you only see the outputs, you think “oh my god it’s alive,” but if you really understood how those outputs are generated, you wouldn’t think anything of the sort.
An LLM can reproduce the language of first-person access without having first-person access. It has been trained on billions of human reports from inside the self-model, so it can output the verbal shape of subjectivity…but the verbal shape of subjectivity is not subjectivity, and a map of the inside is still just a map.
While it’s true that consciousness remains an unsolved mystery, it’s also true that we know a fair bit about it, and have a pretty solid list of animals that show hallmarks of what we call consciousness.
Cetaceans, cephalopods, primates, corvids, canines, felines, elephants, etc. Many animals seem to have a sense of self, emotions, relationships, awareness, language, societies, families, even names.
And do you know what they all have in common?
A physically bounded, persistent self
A complex, highly accurate world model
Complex brains and extensive neurochemistry
Short and long-term memory
Physiological needs
Evolved prime directives (procreation, survival)
A wide range of senses
A wide range of physically felt motions
An LLM, on the other hand, has almost none of these. No true self, no persistence, a buggy world model derived mainly from text (or converting visual data to text/code), crude approximations of “brains,” limited memory, no physiological needs, no evolved prime directives (just goals and rules we’ve provided), limited senses, and no actual emotions.
But because of their mastery of language, and the maps of reality embedded therein, LLMs seem to have all of those things.
But it is only a seeming.
When you go asking it questions you would ask a human, that’s effectively sending the LLM to fish in the topically relevant ponds / weights, and it comes back with the statistically relevant words. And thus the memes:

LLMs are not minds. They are generative compression engines trained on the linguistic residue of minds. They are mimics.
And they show perfectly why the Turing test, while interesting, is only capable of detecting human-likeness, not consciousness. A test of human gullibility more than anything.
Now, that doesn’t mean an AI can never be conscious. If we can be, there’s no fundamental reason I know of that a machine couldn’t become so. I’m a staunch physicalist, and I suspect the right configuration of processing modules can result in the experience we call consciousness, whether in vivo or in silico.
But sorry Richard, LLMs aren’t there yet.
And no, we do not have AGI. (Though we are getting MUCH closer.)